全能创作者
系统管理
应用创建训练与使用
未来鸟:企业数字化转型奔腾的力量!
-
+
首页
应用创建训练与使用
本教程主要针对全能创作者 1.0.6版本中新增的**“应用”**作一说明。说明主要包含应用的**概念和原理、如何创建应用、如何训练应用数据以及如何使用应用**等内容。 比尔盖茨在今年提到:“2022年是AI元年,人类正式进入人工智能时代”,其标志就是GPT 3.5这类大模型的广泛应用,而其延伸chatGPT则是AIGC(AI-Generated Content,生成式人工智能)的典型代表,随着chatGPT的火爆,国内外同期也出现了诸多大模型和其相关应用。 那么,在使用这些AIGC应用的同时,我们会发现**大**多数时候我们仅限于通用问答,或者是基于某些调教文案所限制下的问答,在一些专业性强、对回复质量要求高的领域,通用问答往往无法获得令人满意的结果,此时,我们就需要引入某个领域或者行业的专业数据来辅助人工智能,针对这样的场景,各个AIGC服务提供商引入了**基于向量数据库+Embeddings**[[1]](#footnote-0)的手段,来帮助用户创建属于自己的专属知识库,从而让AI生成的问题更加的专业和精准。 ### 1. 应用的概念和原理 全能创作者的**“应用”是利用向量数据库和Embeddings技术来加工、存储行业、领域专有数据,并对终端用户提供这些数据的语义检索和文本二次加工服务**。以下是“应用”的流程图: 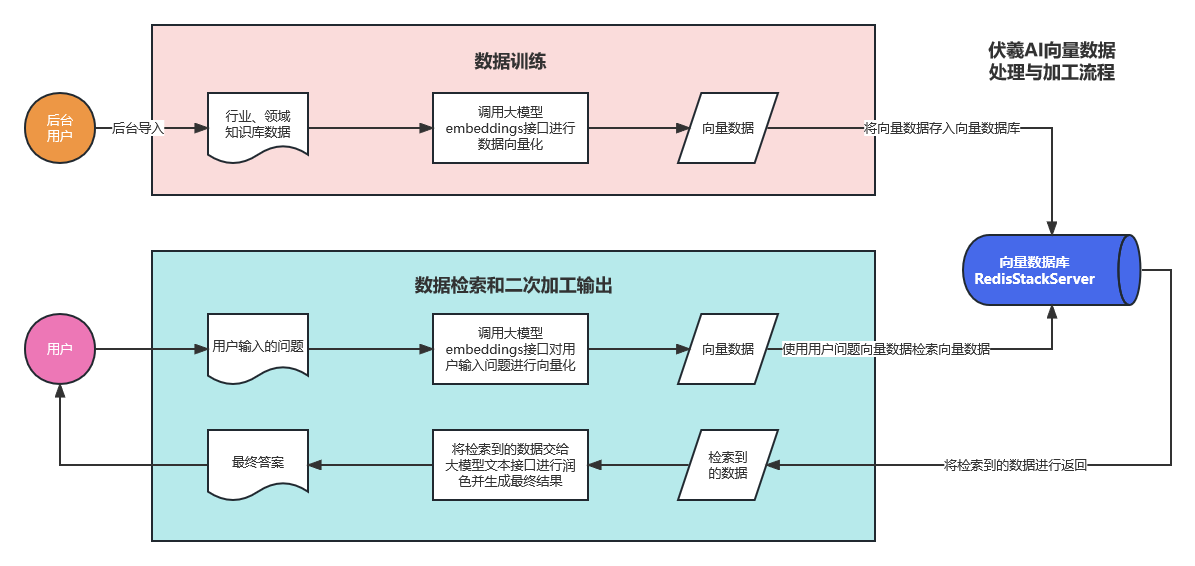 全能创作者向量数据处理与加工流程图 从上图可以看出,应用从大的流程上来说分为数据训练、数据检索和输出,我们来分别说明一下。 #### **数据训练**: 后台用户通过在后台将行业、领域知识库数据进行导入-->**大模型的embeddings接口对这些数据逐条进行向量化处理**-->程序将这些向量数据存入向量数据库。 #### **数据检索和输出**: 终端用户输入问题-->大模型的embeddings接口对用户输入问题进行向量化处理-->**用被处理后的用户问题向量去向量库进行检索(语义检索[[2]](#footnote-1),全能创作者采用KNN算法[[3]](#footnote-2))**-->程序将检索到的数据**利用大模型文本接口进行加工润色**-->形成最终答案返回给用户。 ### 2. 如何创建应用 #### (1)创建应用分类 首先进入全能创作者后台管理,并在左侧导航菜单中选择[应用]-->[应用分类]。 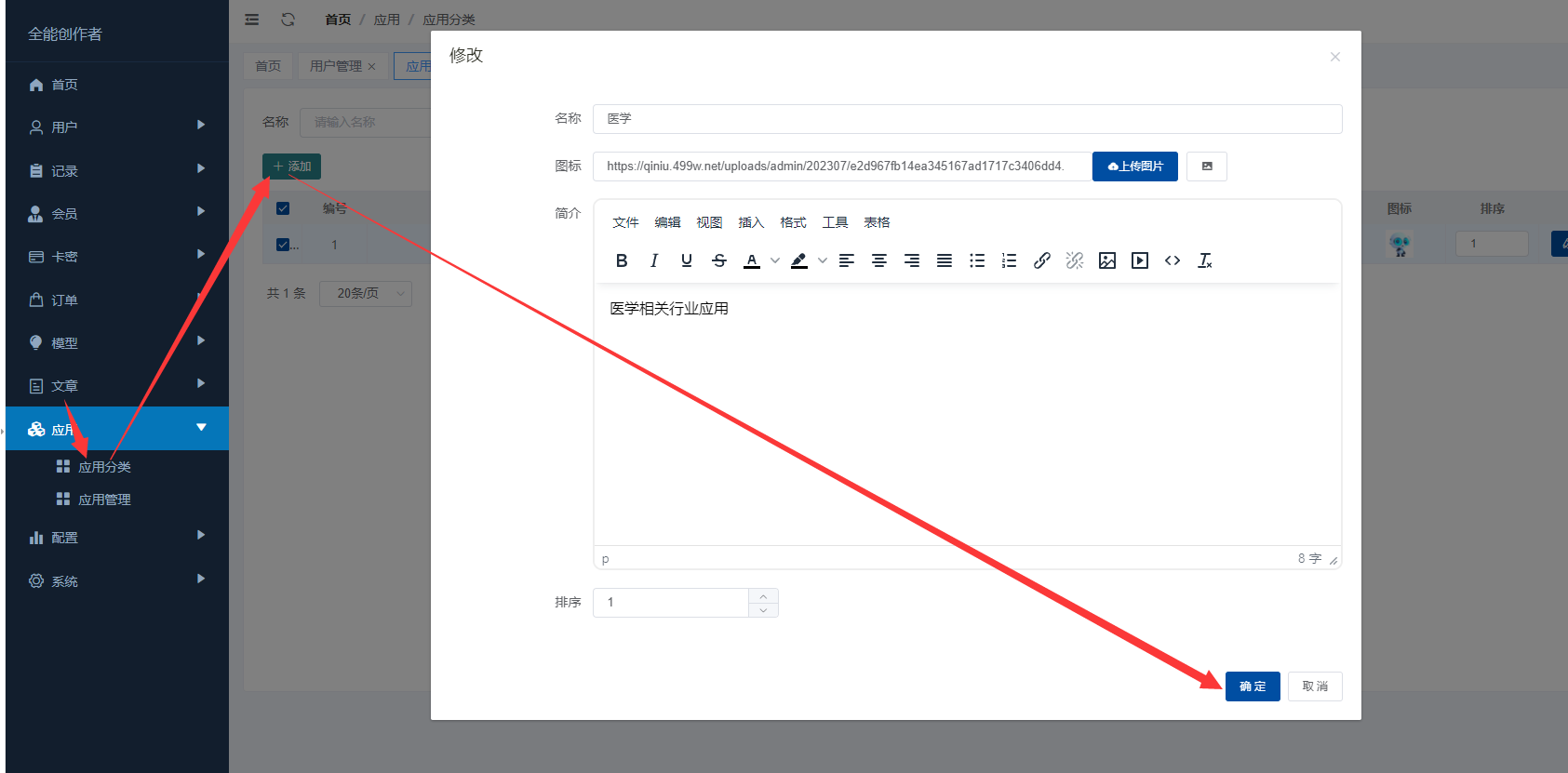 如图所示,进入应用分类后,点击添加按钮,在弹出的对话框中输入分类相关信息后,点击右下角确定按钮进行应用分类的创建。 ##### (2) 创建应用 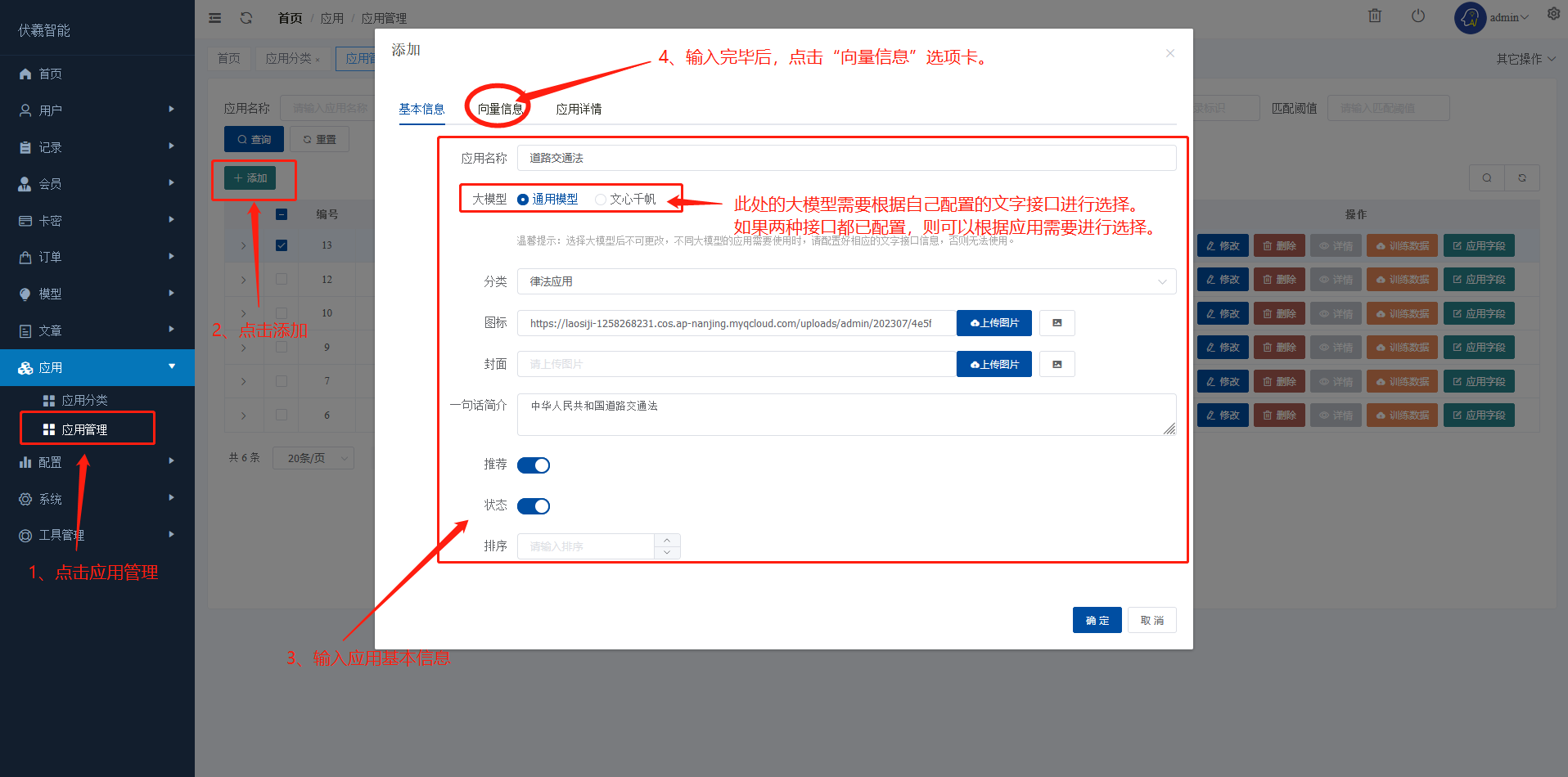 点击后台左侧导航菜单中的[应用]-->[应用管理],进入应用管理界面。 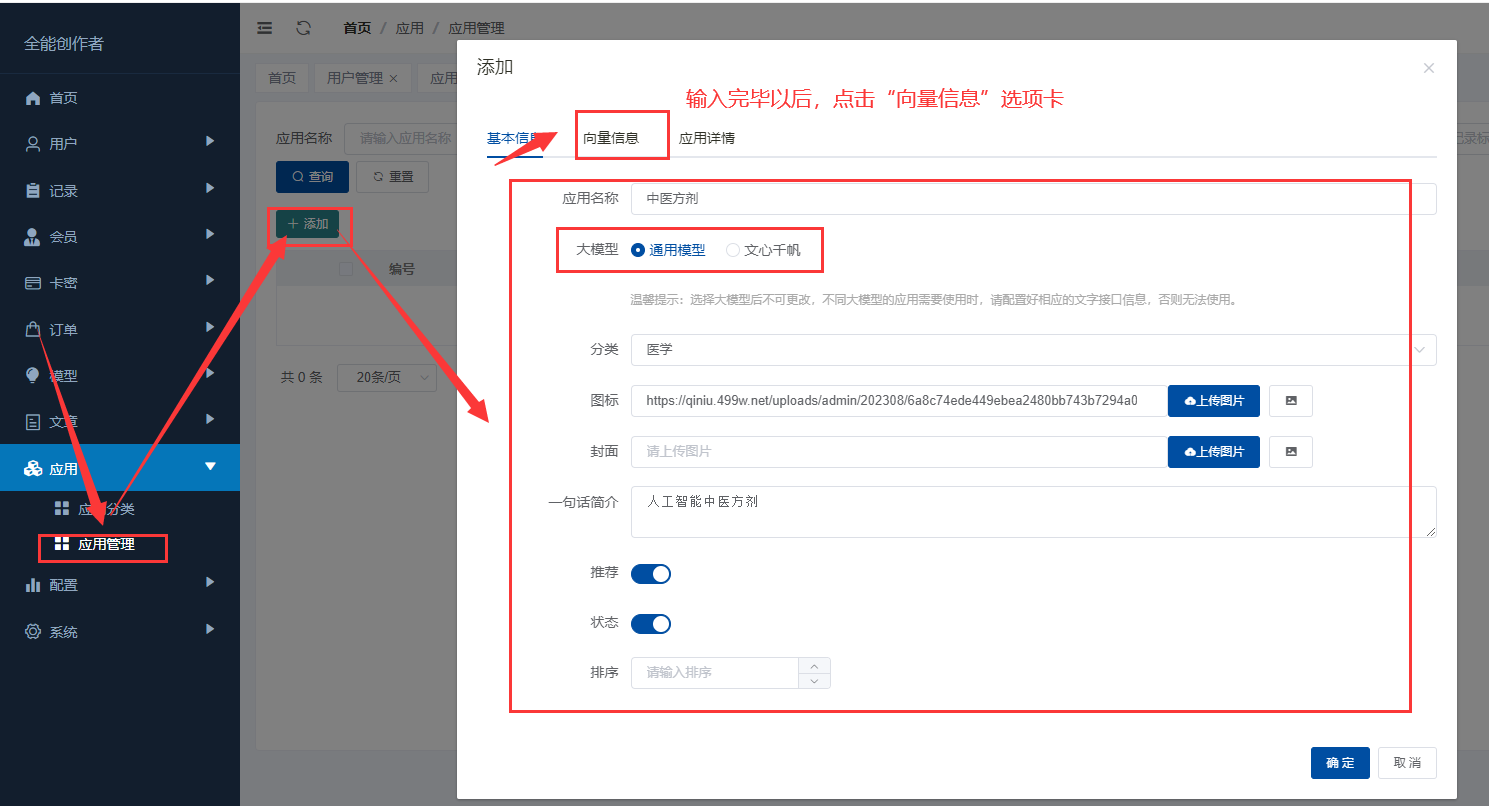 如上图所示,进入应用管理,点击添加按钮,在弹出的对话框中输入相应的信息,输入完毕后切换选项卡到“向量信息”。  ==关于大模型:根据自己配置的文字接口进行选择,如果两种接口都已配置,则可以根据应用需要进行选择。== 如上图所示,首先我们输入索引标识,索引标识注意不要与之前应用的索引标识重复,索引的概念相当于该应用在向量数据库中的表,然后再输入记录标识,记录标识一般在索引标识后加上\_r即可,例如索引标识为medicine,记录标识即可命名为:medicine\_r。输入完毕后,请选择“应用详情”选项卡。  在应用详情选项卡中,输入相应的应用详情信息,然后点击确定按钮,完成应用的创建。 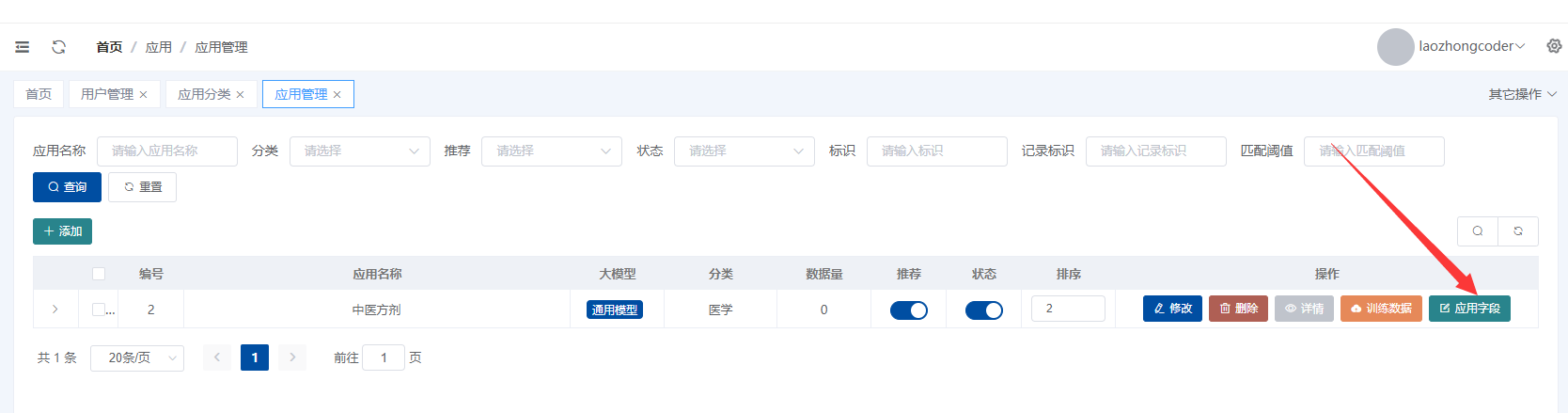 完成应用创建后,我们**首先需要在该应用创建字段**,如上图所示,点击创建好的应用最右侧的应用字段,打开应用字段弹窗。 下面我们来演示说明**最简单的一种情况,即:应用只存在一个向量字段。** 在应用字段弹窗的左上角点击添加按钮,弹出应用字段添加弹窗。 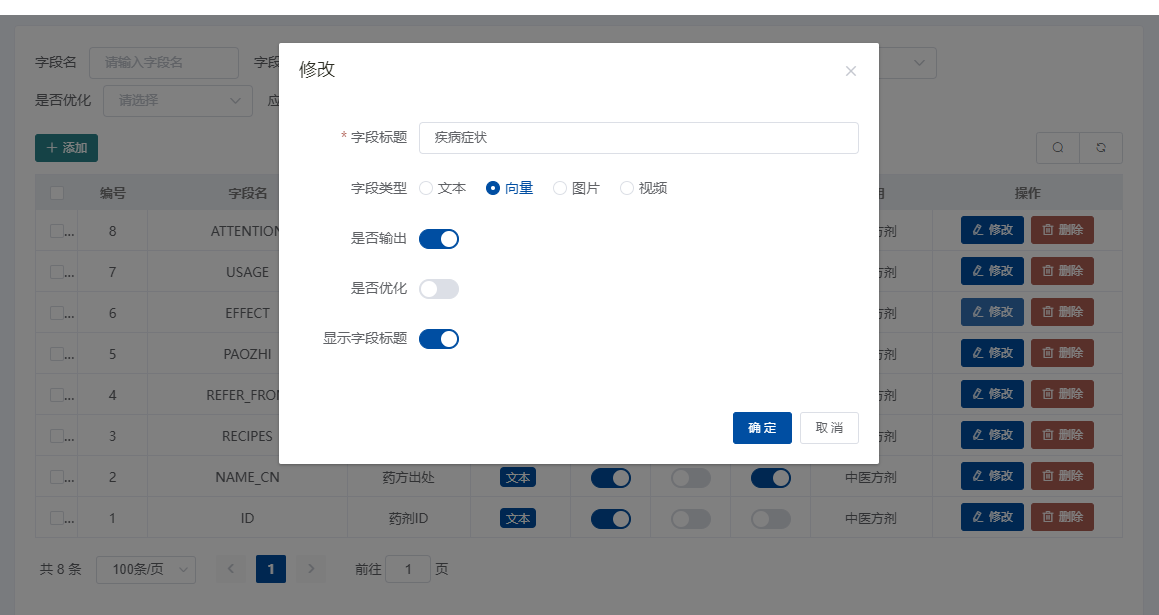 如上图所示,在弹窗中输入字段名(**必须英文**)、字段标题(中文)、选择字段类型、是否输出(是否展示在前端)、是否优化(检索到的结果是否经过大模型的二次加工)、显示字段标题(前端是否显示字段标题),点击确定完成字段创建。 字段创建完成后,返回到应用字段,**此时务必要点击[创建索引]按钮,完成该应用的索引创建**,方可进行下面的训练工作,如下图所示。 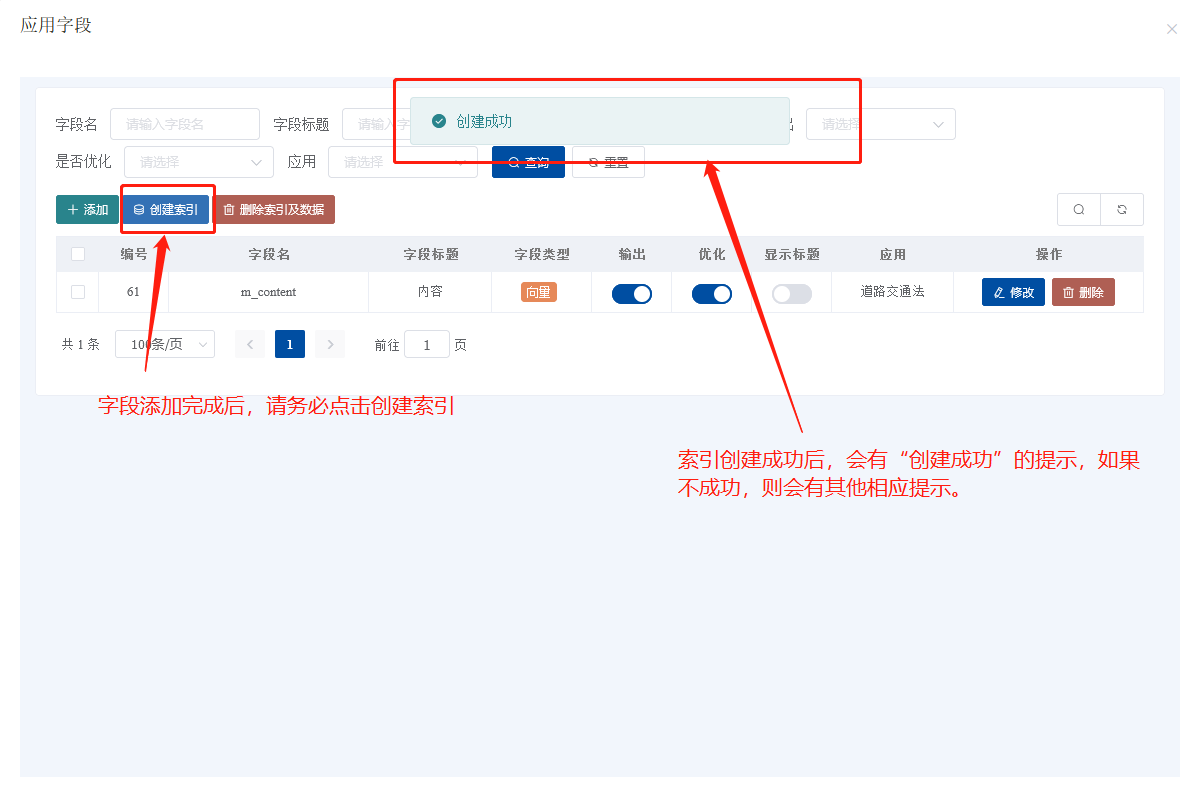 索引创建成功后,关闭应用字段对话框,返回应用列表,我们开始下一步:训练应用数据。 ### 3. 如何训练应用数据 训练应用数据前,我们需要先准备好相应的数据文件,目前全能创作者采用excel文件导入的形式,在后续版本中会支持word、txt等类型的文件导入。 以上一步创建的应用为例,我们创建了一个道路交通法的应用,其中包含一个m\_content字段,所以我们在excel文件中就需要创建一列数据,列名为m\_content,如下图所示:  准备好导入的Excel文件后,我们在应用列表界面,点击相应应用右侧的“训练数据”按钮,弹出训练数据对话框。 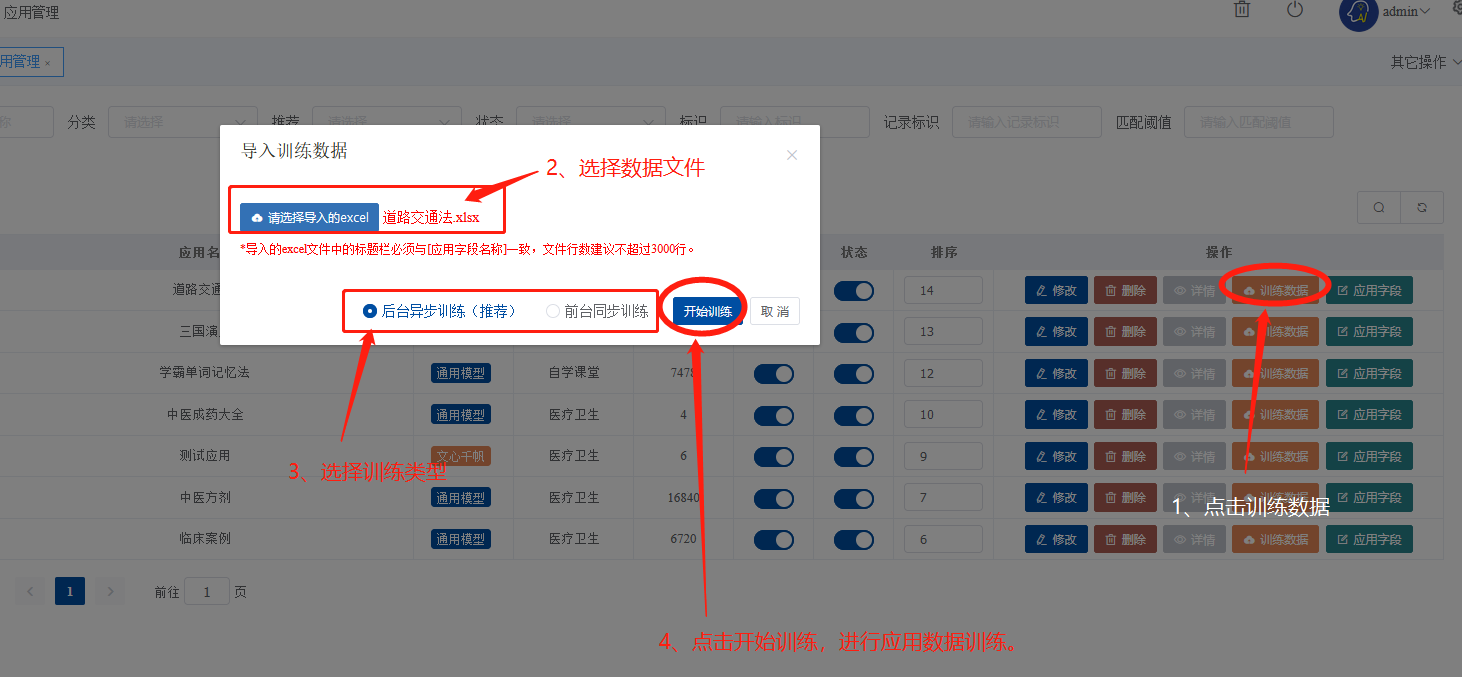 如上图所示,首先点击“请选择导入的excel”按钮,选择我们刚才准备好的数据文件,然后选择训练类型,训练类型分为两种: 1. **后台异步训练**:该类型为后台异步队列训练的方式,简单地说即先导入、后训练的方式,导入完成后(导入完成前不可刷新界面)即可进行其他工作,系统后台会自动进行数据训练。 2. **前台同步训练**:导入一条训练一条的方式,前台显示实时训练进度,该方式优点是能实时掌控训练进度,缺点是只能等待训练完毕方可进行其他工作。 我们这里选择后台异步训练的方式,然后点击“开始训练”按钮,对话框会显示导入进度,导入完成后会显示“导入完成”的提示。如下图所示。 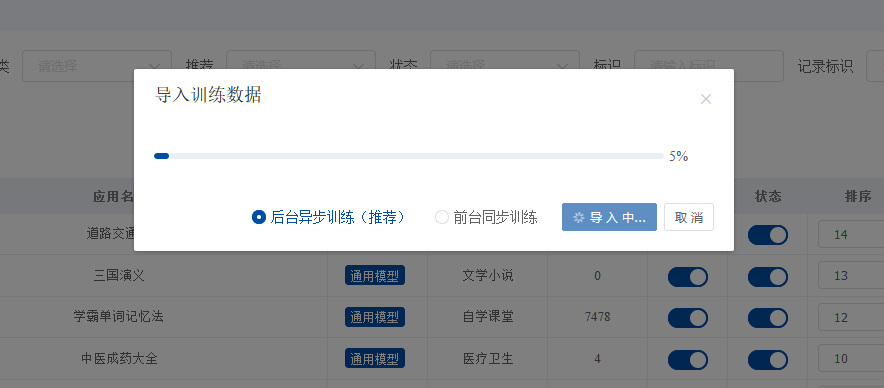 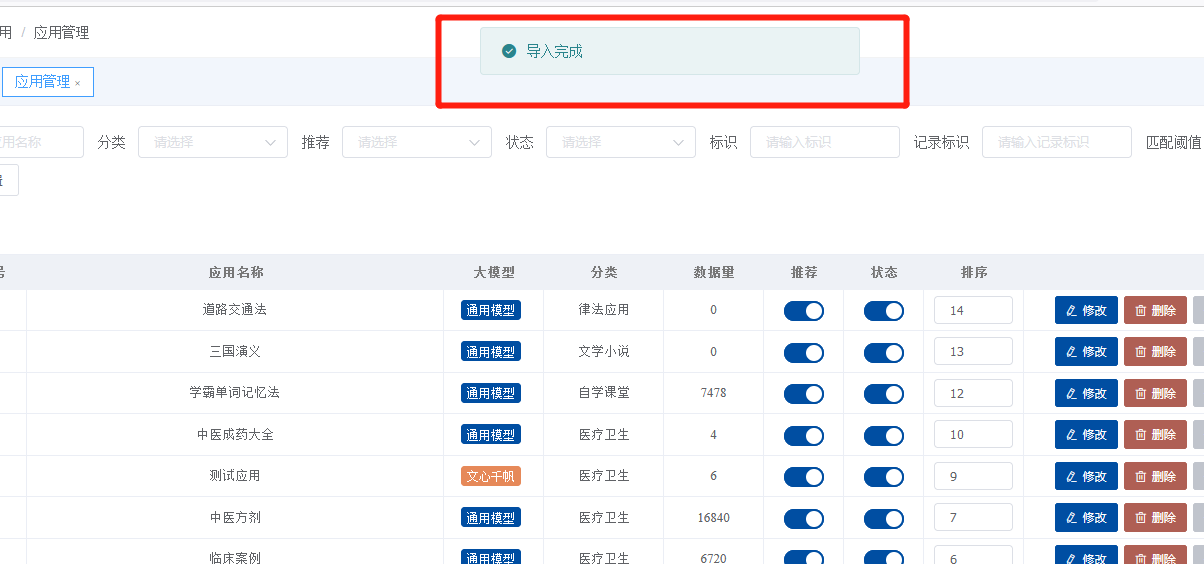 导入完成后,我们可以刷新下应用列表,可以看到该应用的“数据量”字段,开始有数字(该数字代表已经训练完成的数据量)增加,即代表后台已经在训练数据了。如下图所示。 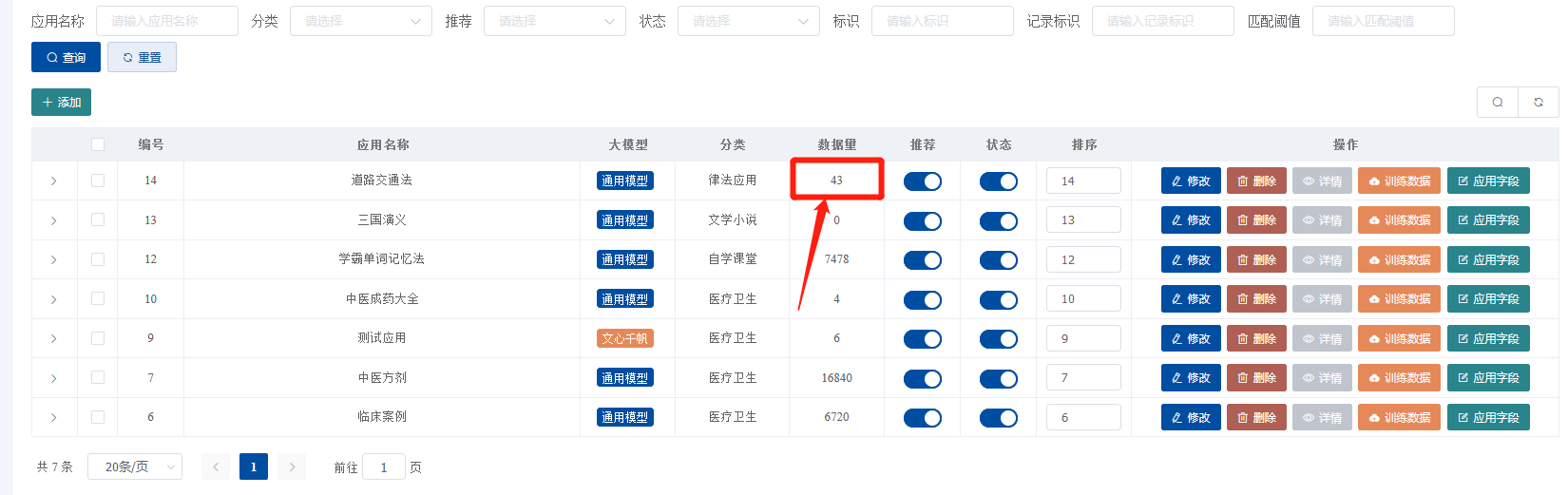 当训练数字与我们Excel文件中的记录一致时,即代表训练完成,我们可以到全能创作者前端进行检索了。 值得注意的是,由于训练操作调用的是各个大模型的embeddings接口,受限于对方接口、我们自身服务器环境、网络抖动等因素,偶尔会有训练不成功的情况出现,造成最终训练成功的数据量与excel文件中的记录数不一致的情况出现,这属于正常现象,可以通过查看后台错误日志的方式检查哪些数据没有训练成功。 ### 4. 如何使用应用 进入全能创作者前台,点击行业应用或者直接通过首页推荐应用的方式进入刚才我们训练好的应用,如下图所示。 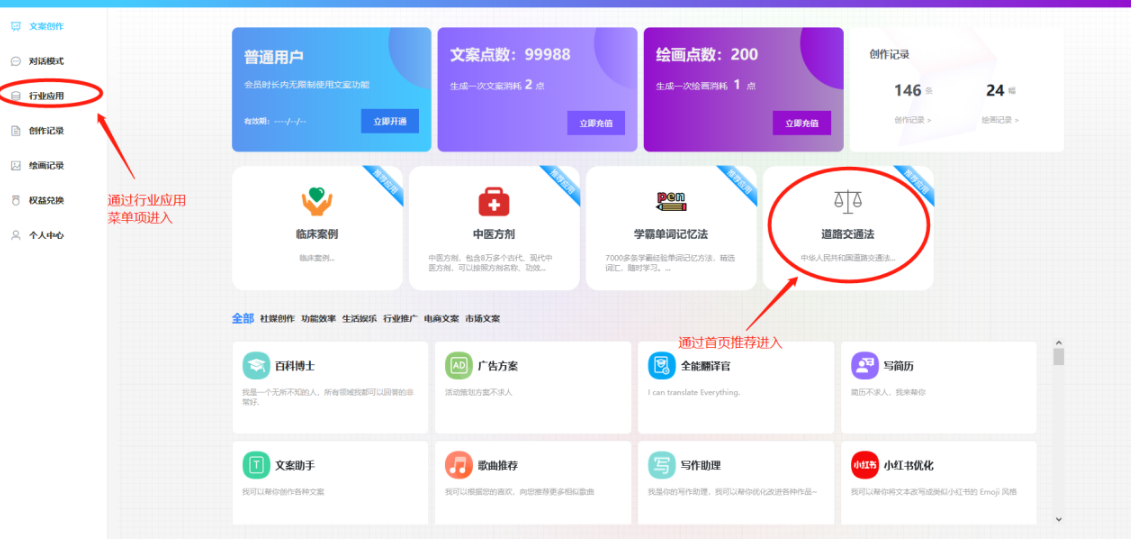 进入应用后,在相应的文本框输入您要问的问题,然后点击立即查询,右侧会输出相应的答案。如下图所示。 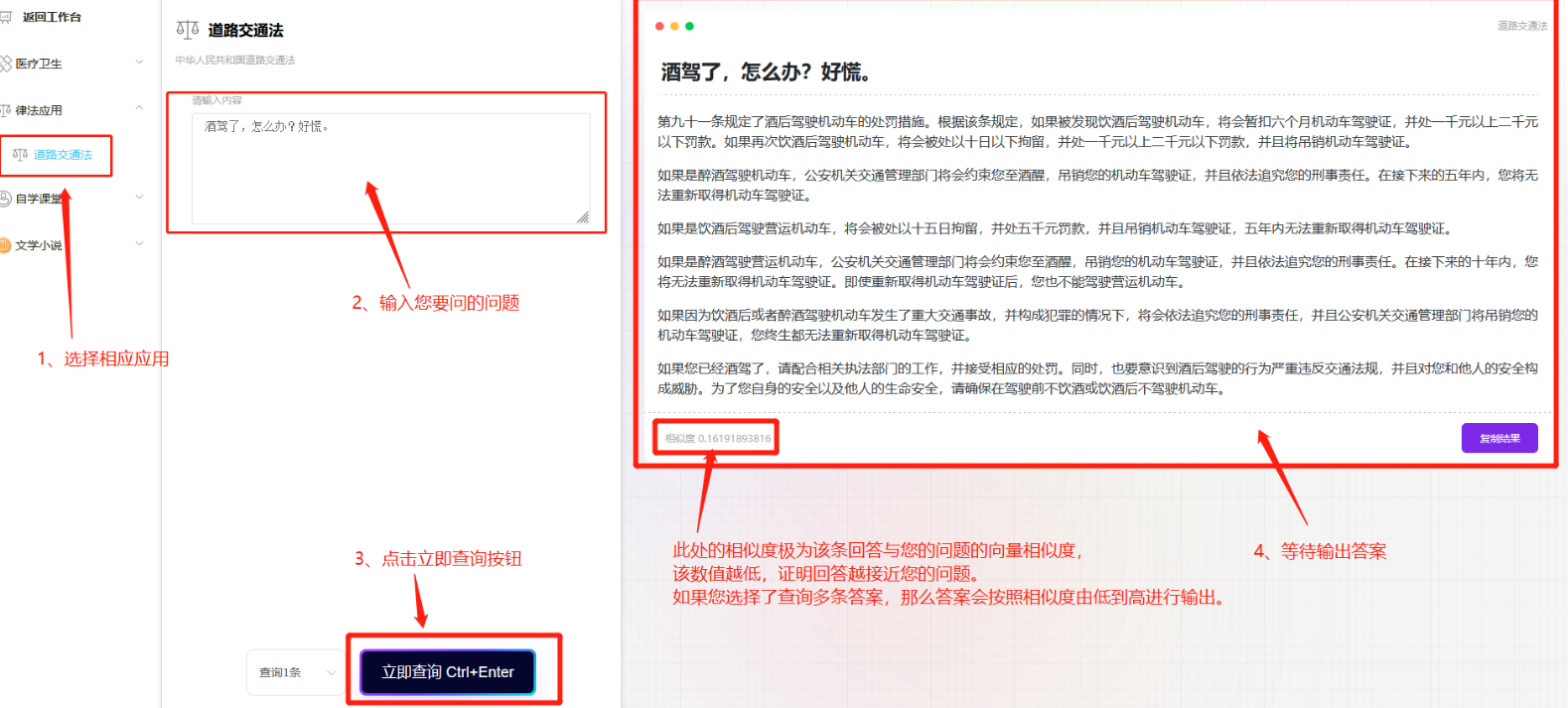 目前,应用的答案输出是经过统一调教的,接下来的版本中,会对应用添加相应的调教设置,让应用能够根据用户调教进行相应的输出,以上就是单向量字段应用的创建、训练和使用的说明。 应用检索和输出的效果,与你导入的数据质量息息相关,所以一定要提前做好导入数据的加工处理,尽量按照具备完整意义的段落进行文本拆分。 另外,**本系统应用还有一个较大的特点,就是支持多字段应用的创建,字段类型包含文本、图片、视频、向量四种**,我们将单独撰写一篇文章来进行说明。有能力的用户也可根据本篇教程,自行摸索如何配置多字段应用。 #### 1. **embedding** 直接翻译为“嵌入”,实际上我们可以理解为“向量映射”,即现实中所有的实体均可用向量来表示,本文处理的主要是文本向量,市面上各个大模型的embeddings接口提供的即是数据的向量映射服务,简单地说,就是将你提供的数据(例如文本)转换为多维向量。 [↑](#footnote-ref-0) #### 2. **语义检索**: 不拘泥于用户所输入语句的字面本身,而是透过现象看本质,准确地捕捉到用户所输入语句后面的真正意图,并以此来进行搜索,从而更准确地向用户返回最符合其需求的搜索结果。 [↑](#footnote-ref-1) #### 3. **KNN算法**: K-Nearest Neighbors,一种基本的机器学习算法,用于分类和回归问题。该算法根据样本之间的距离度量,在训练数据集中找到与待分类样本最近邻的K个样本,并基于这K个样本进行分类或回归。KNN算法的核心思想是“近朱者赤,近墨者黑”,即认为距离上接近的样本在特征空间中具有相似的性质。 [↑](#footnote-ref-2)
未来鸟
2023年8月2日 16:23
转发
收藏文档
上一篇
下一篇
手机扫码
复制链接
手机扫一扫转发分享
复制链接
Markdown文件
Word文件
PDF文档
PDF文档(打印)
分享
链接
类型
密码
更新密码
有效期
AI